介绍
本文主要介绍一些二叉树结构,代码语言为 golang,地址:
二叉树
二叉树(Binary Tree)是包含 n 个节点的有限集合,该集合或者为空集(此时,二叉树称为空树),或者由一个根节点和两棵互不相交的、分别称为根节点的左子树和右子树的二叉树组成。
二叉查找树
满足左大右小即可,是一种非常简单的二叉树
- 插入使用递归,从上到下查找新节点在树种的合适位置
- 删除时候需分以下三种情况进行考虑:

AVL 树
AVL 树的基本操作一般涉及运作同在不平衡的二叉查找树所运作的同样的算法。但是要进行预先或随后做一次或多次所谓的”AVL 旋转”。
插入
以下图表以四列表示四种情况,每行表示在该种情况下要进行的操作。在左左和右右的情况下,只需要进行一次旋转操作;在左右和右左的情况下,需要进行两次旋转操作。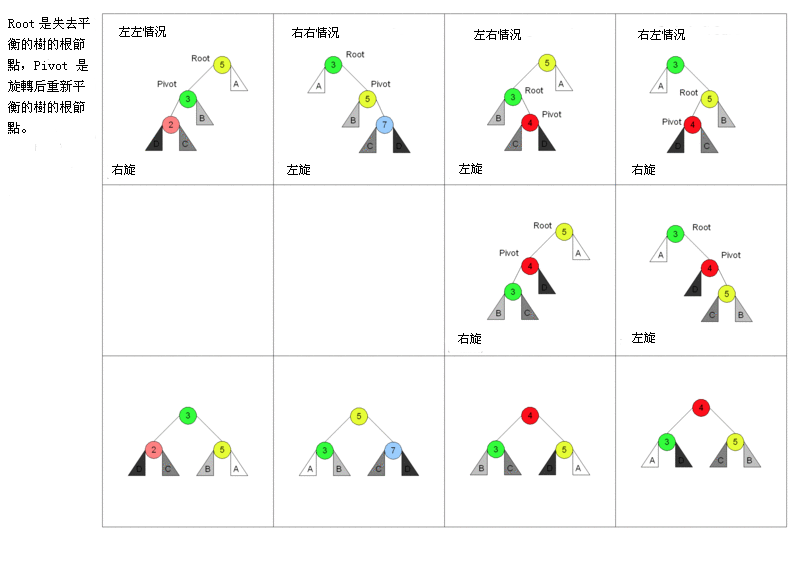
删除
从 AVL 树中删除,可以通过把要删除的节点向下旋转成一个叶子节点,接着直接移除这个叶子节点来完成。因为在旋转成叶子节点期间最多有 log n 个节点被旋转,而每次 AVL 旋转耗费固定的时间,所以删除处理在整体上耗费 O(log n) 时间。- 搜索
可以像普通二叉查找树一样的进行,所以耗费 O(log n)时间,因为 AVL 树总是保持平衡的。不需要特殊的准备,树的结构不会由于查找而改变。(这是与伸展树搜索相对立的,它会因为搜索而变更树结构。)
红黑树
B 树
B+树
B*树
Trie 树
HAT-Trie
前缀树
Generalized Prefix Tree (GPT)
后缀树
Succinct Trie
基数(Radix)树
对于长整型数据的映射,如何解决 Hash 冲突和 Hash 表大小的设计是一个很头疼的问题。
radix 树就是针对这种稀疏的长整型数据查找,能快速且节省空间地完成映射。借助于 Radix 树,我们可以实现对于长整型数据类型的路由。利用 radix 树可以根据一个长整型(比如一个长 ID)快速查找到其对应的对象指针。这比用 hash 映射来的简单,也更节省空间,使用 hash 映射 hash 函数难以设计,不恰当的 hash 函数可能增大冲突,或浪费空间。
radix tree 是一种多叉搜索树,树的叶子结点是实际的数据条目。每个结点有一个固定的、2^n 指针指向子结点(每个指针称为槽 slot,n 为划分的基的大小)
radix Tree(基数树) 其实就差不多是传统的二叉树,只是在寻找方式上,利用比如一个 unsigned int 的类型的每一个比特位作为树节点的判断。
可以这样说,比如一个数 1000101010101010010101010010101010,那么按照 Radix 树的插入就是在根节点,如果遇到 0,就指向左节点,如果遇到 1 就指向右节点,在插入过程中构造树节点,在删除过程中删除树节点。如果觉得太多的调用 Malloc 的话,可以采用池化技术,预先分配多个节点。
(使用一个比特位判断,会使树的高度过高,非叶节点过多。故在实际应用中,我们一般是使用多个比特位作为树节点的判断,但多比特位会使节点的子节点槽变多,增大节点的体积,一般选用 2 个或 4 个比特位作为树节点即可)
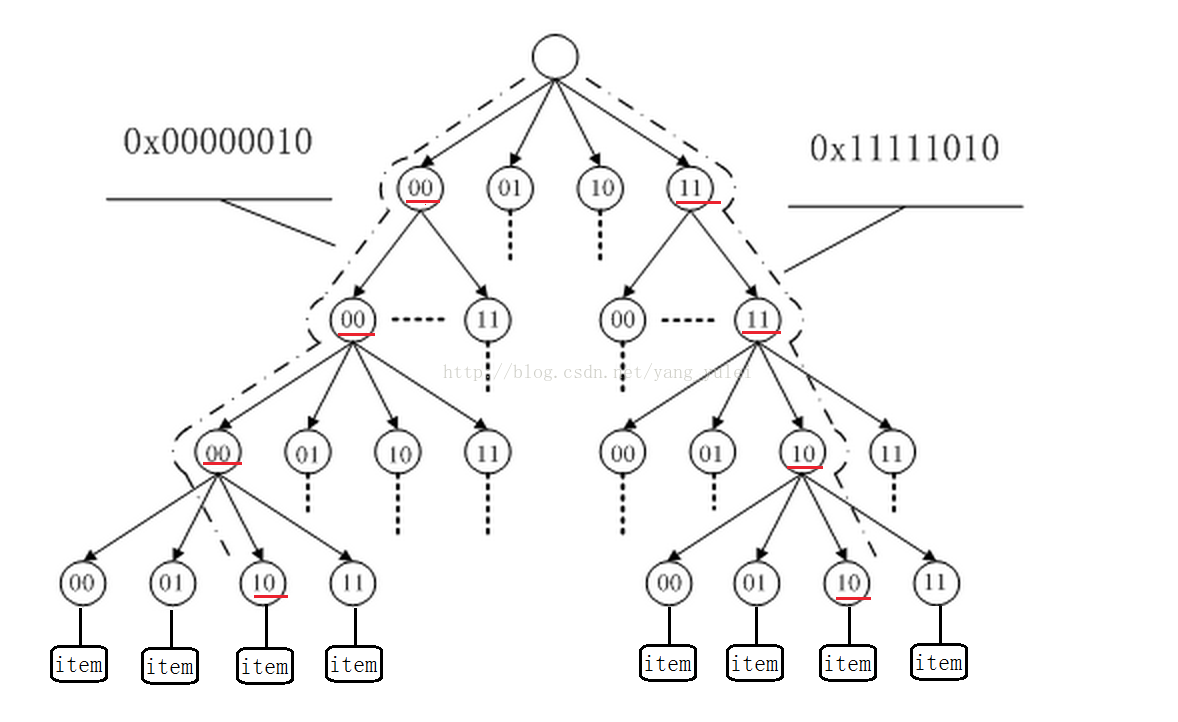
Radix 树在 Linux 中的应用:
Linux 基数树(radix tree)是将 long 整数键值与指针相关联的机制,它存储有效率,并且可快速查询,用于整数值与指针的映射(如:IDR 机制)、内存管理等。
IDR(ID Radix)机制是将对象的身份鉴别号整数值 ID 与对象指针建立关联表,完成从 ID 与指针之间的相互转换。IDR 机制使用 radix 树状结构作为由 id 进行索引获取指针的稀疏数组,通过使用位图可以快速分配新的 ID,IDR 机制避免了使用固定尺寸的数组存放指针。IDR 机制的 API 函数在 lib/idr.c 中实现。
Linux radix 树最广泛的用途是用于 内存管理,结构 address_space 通过 radix 树 跟踪绑定到地址映射上的核心页,该 radix 树允许内存管理代码快速查找标识为 dirty 或 writeback 的页。其使用的是数据类型 unsigned long 的固定长度输入的版本。每级代表了输入空间固定位数。Linux radix 树的 API 函数在 lib/radix-tree.c 中实现。(把页指针和描述页状态的结构映射起来,使能快速查询一个页的信息。)
Linux 内核利用 radix 树在文件内偏移快速定位文件缓存页。
Linux(2.6.7) 内核中的分叉为 64(2^6),树高为 6(64 位系统)或者 11(32 位系统),用来快速定位 32 位或者 64 位偏移,radix tree 中的每一个叶子节点指向文件内相应偏移所对应的 Cache 项。
radix 树为稀疏树提供了有效的存储,代替固定尺寸数组提供了键值到指针的快速查找。
Radix 树与 Trie 树的思想有点类似,甚至可以把 Trie 树看为一个基为 26 的 Radix 树。(也可以把 Radix 树看做是 Tire 树的变异)
Trie 树一般用于字符串到对象的映射,Radix 树一般用于长整数到对象的映射。
trie 树主要问题是树的层高,如果要索引的字的拼音很长很变态,我们也要建一个很高很变态的树么?
radix 树能固定层高(对于较长的字符串,可以用数学公式计算出其特征值,再用 radix 树存储这些特征值)
插入
我们在插入一个新节点时,我们根据数据的比特位,在树中向下查找,若没有相应结点,则生成相应结点,直到数据的比特位访问完,则建立叶节点映射相应的对象。删除
我们可以“惰性删除”,即沿着路径查找到叶节点后,直接删除叶节点,中间的非叶节点不删除。
ART 树
KISS 树
FAST 树
- pointer-free
- no online
- k-ary
- GPU implementation
T 树
R 树
R+树
R*树
QR 树
SS 树
X 树
参考文献
- [Data Structure] 数据结构中各种树 http://www.cnblogs.com/maybe2030/p/4732377.html
- ARThttps://db.in.tum.de/~leis/papers/ART.pdf
- 内存数据库中的索引技术https://blog.csdn.net/zhujunxxxxx/article/details/42490335